本文只作为知识点总结,无不良引导。使用爬虫有一定的法律风险,请大家合理利用爬虫工具。
前段时间复习了一下爬虫的相关使用方式,又有了一些新的收获,来博客做一个记录。各位大佬如果有更好用的技巧,请务必指点我🙏
源代码地址 爬取 Packet storm 上的 POC 注意:GitHub上本案例的代码使用了selenium,之前测试用,但是代码还是能正常跑的,不用担心。scrapy调用driver需要一些时间,运行时如果遇到这样的提示信息,不用着急,等一会儿会跑起来,前提是selenium和driver配置正确。
分析:
思路:
主要代码简析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def parse_vul_list (self, response ): counter = 0 vul_list = response.xpath('//a[@class="ico text-plain"]/@href' ).extract() for vul in vul_list: counter += 1 if counter >= 2 : break vul_url = 'https://packetstormsecurity.com' + vul request = scrapy.Request(url=vul_url, callback=self.parse_vul_inf) yield request def parse_vul_inf (self, response ): item = {} item['title' ] = response.xpath('//strong/text()' ).extract_first() if response.xpath( '//strong/text()' ).extract_first() else '' authors = response.xpath('//a[@class="person"]/text()' ).extract() if response.xpath( '//a[@class="person"]/text()' ).extract() else '' item['author' ] = ',' .join(authors) date = response.xpath('//dd[@class="datetime"]/a/@href' ).extract_first() if response.xpath( '//dd[@class="datetime"]/a/@href' ).extract_first() else '' pattern = re.compile (r'/files/date/(.*?)' ) item['date' ] = pattern.findall(date)[0 ] item['des' ] = response.xpath('//dd[@class="detail"]/p/text()' ).extract_first() if response.xpath( '//dd[@class="detail"]/p/text()' ).extract_first() else '' item['vul_type' ] = '' cveid = response.xpath('//dd[@class="cve"]/a/text()' ).extract() if response.xpath( '//dd[@class="cve"]/a/text()' ).extract() else '' item['CVE-ID' ] = ',' .join(cveid) test = response.xpath('//div[@class="src"]/pre/code/text()' ).extract_first() if response.xpath( '//div[@class="src"]/pre/code/text()' ).extract_first() else '' s_replace = test.replace('<br>' , '' ) s_replace = s_replace.replace('<code>' , '' ) s_replace = s_replace.replace('</code>' , '' ) item['poc' ] = s_replace yield item
这个案例还对请求头 做了处理,这样不容易被发现。
爬取豆瓣top250电影信息 该案例的爬取数据会用于之后的NLP练习。
思路:
主要代码简析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 def parse (self, response ): node_list = response.xpath('//div[@class="info"]' ) for msg in node_list: details_url = msg.xpath('./div[@class="hd"]/a/@href' ).extract() name_chinese = msg.xpath('./div[@class="hd"]/a/span[1]/text()' ).extract() name = msg.xpath('./div[@class="hd"]/a/span[2]/text()' ).extract() name = str (name).replace("\\xa0" , "" ).replace("/" , "" ) name_other_list = msg.xpath('./div[@class="hd"]/a/span[3]/text()' ).extract() name_other_list = str (name_other_list).replace("\\xa0" , "" ).replace("/" , "" ) player_type = msg.xpath('./div[@class="hd"]/span[@class="playable"]/text()' ).extract() player_type = str (player_type)[3 :-3 ] number_evaluate = msg.xpath('./div[@class="bd"]/div[@class="star"]/span[4]/text()' ).extract() number_evaluate = str (number_evaluate)[2 :-5 ] score = msg.xpath('./div[@class="bd"]/div[@class="star"]/span[@property="v:average"]/text()' ).extract() purpose = msg.xpath('./div[@class="bd"]/p[@class="quote"]/span[@class="inq"]/text()' ).extract() item_pipe = DoubanspiderItem() item_pipe["details_url" ] = details_url item_pipe["name_chinese" ] = name_chinese item_pipe["name" ] = name item_pipe["name_other_list" ] = name_other_list item_pipe["player_type" ] = player_type item_pipe["number_evaluate" ] = number_evaluate item_pipe["score" ] = score item_pipe["purpose" ] = purpose time.sleep(self.step_time) yield Request(details_url[0 ], callback=self.get_details, meta={"info" : item_pipe}) self.page_number += 1 print (self.page_number) if self.page_number < 10 : time.sleep(3 ) page_url = 'https://movie.douban.com/top250?start={}&filter=' .format (self.page_number * 25 ) yield scrapy.Request(page_url, callback=self.parse) def get_details (self, response ): item_pipe = DoubanspiderItem() info = response.meta["info" ] item_pipe.update(info) response = response.xpath('//div[@id="info"]' ) writer_list = response.xpath('./span[2]/span[@class="attrs"]/a/text()' ).extract() if response.xpath( './span[2]/span[@class="attrs"]/a/text()' ).extract() else '' director_list = response.xpath('./span[1]/span[@class="attrs"]/a/text()' ).extract() if response.xpath( './span[1]/span[@class="attrs"]/a/text()' ).extract() else '' star_list = response.xpath('string(./span[@class="actor"]/span[@class="attrs"])' ).extract() if response.xpath( 'string(./span[@class="actor"]/span[@class="attrs"])' ).extract() else '' official_url = response.xpath('./a[@rel="nofollow" and @target="_blank"]/@href' ).extract() if response.xpath( './a[@rel="nofollow" and @target="_blank"]/@href' ).extract() else '' release_data = response.xpath('./span[@property="v:initialReleaseDate"]/text()' ).extract() if response.xpath( './span[@property="v:initialReleaseDate"]/text()' ).extract() else '' area = str (response.extract()) area = area[area.index("制片国" ):area.index("语言" )].strip() area = area[area.index("</span>" ) + 7 :area.index("<br>" )].strip() if area[area.index("</span>" ) + 7 :area.index( "<br>" )].strip() else '' languages = str (response.extract()) languages = languages[languages.index("语言" ):languages.index("上映" )].strip() languages = languages[languages.index("</span>" ) + 7 :languages.index("<br>" )].strip() times = response.xpath('./span[@property="v:runtime"]/text()' ).extract() film_type = response.xpath('./span[@property="v:genre"]/text()' ).extract() item_pipe["writer_list" ] = writer_list item_pipe["director_list" ] = director_list item_pipe["star_list" ] = star_list item_pipe["official_url" ] = official_url item_pipe["release_data" ] = release_data item_pipe["area" ] = area item_pipe["languages" ] = languages item_pipe["times" ] = times item_pipe["film_type" ] = film_type yield item_pipe
爬取安居客二手房数据 两年前写的,不能保证现在是否还有效,前段时间看的时候好像不行了,但逻辑应该还能使用,应该只需要修改修改就能跑,自行了解。
爬取 Exploit-db 上的 POC 本案例我们需要爬取的内容就是动态加载的资源。关于网站的静态和动态资源,可以参考我写的这篇网站资源类型及其加速原理 。简单来说,静态网页是在服务器端生成并发送给客户端的固定内容 ,内容在客户端展示时并不会发生变化。而动态网页则是在客户端加载和渲染过程中,通过JavaScript等脚本技术 动态生成和更新内容。这使得动态网页的内容无法通过简单地下载HTML源码来获取,而需要模拟浏览器行为来执行脚本并获取最终呈现的内容。
我一开始还是想通过Scrapy 来爬取的,但是会发现这个网站存在异步加载,那么Scrapy提供的下载器就不是那么好用了,或者可以说失效了。因为这部分数据需要在客户端加载,而下载器无法渲染这部分数据,所以直接使用Scrapy ,是得不到我们想要的POC数据的。
然后就想着使用Scrapy+Selenium ,通过编写中间件,用selenium 去模拟浏览器的行为,从而得到那一部分数据的response 。很遗憾,我并没有成功,理论上应该是可行的,应该是代码写的有点问题,运行结果有返回的response,但里面还是没有需要的数据。这种思路应该是正确的,之后可以继续研究一下。
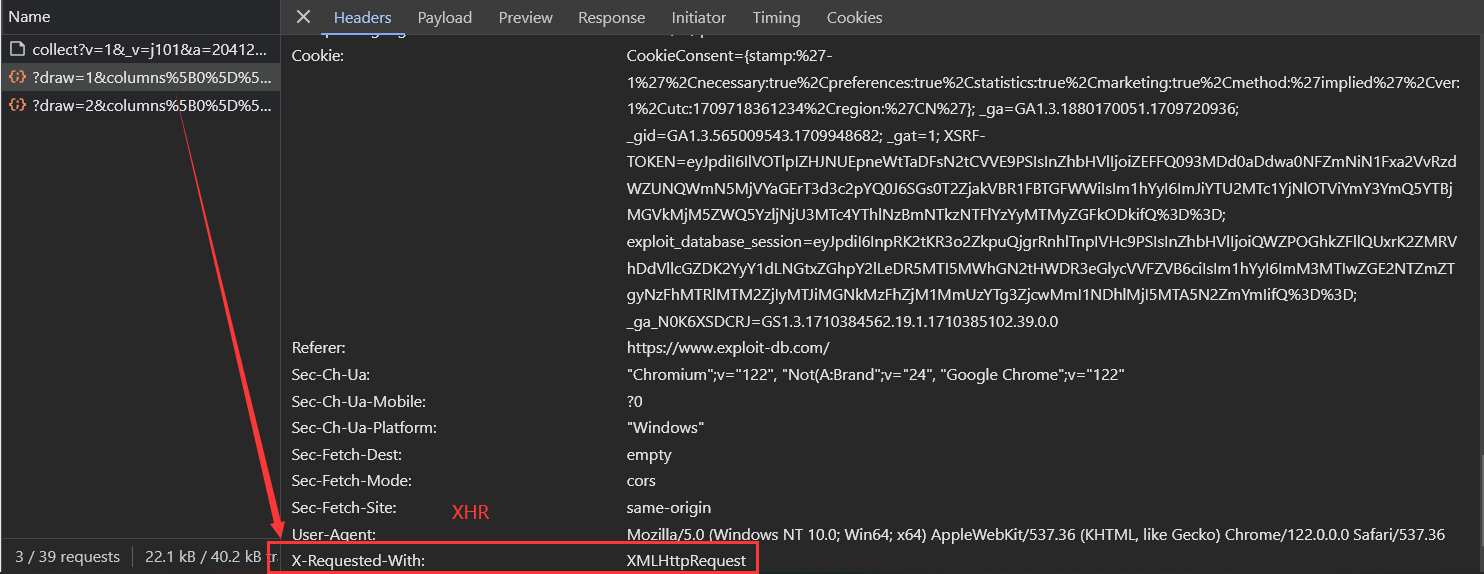
观察响应:
既然这条路走不通,我就直接上selenium ,不仅成功了,代码也挺简洁的。开始的两个案例当然也能使用selenium爬取,但一般不会这么做,因为效率会降低。selenium主要还是用在动态网站的数据爬取上。
思路:异步加载 ,所以需要借助selenium 等自动工具模拟浏览器的行为,从而渲染得到所需数据。只要渲染成功,爬取步骤与静态网页的爬取类似。
关于本案例网站的异步加载 本案例中目标网站使用了Ajax,依据:
关于Ajax,大家可以学习这个视频,简单了解什么是Ajax:
简单来说,Ajax 并不算是一种新的技术,而是已有技术的组合,主要用来实现客户端与服务器端的异步通信效果,实现页面的局部刷新。Ajax的目的是提高用户体验,较少网络数据的传输量,所以它不是一种反爬技术 ,只是它的异步加载 使得不能像爬取静态网页那样制作爬虫。
主要代码简析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 driver = webdriver.Chrome() url = "https://www.exploit-db.com/" driver.get(url) wait = WebDriverWait(driver, 10 ) element = wait.until(EC.visibility_of_element_located((By.XPATH, '//tbody/tr[@role="row"]/td[5]/a' ))) links = driver.find_elements(By.XPATH, "//tbody/tr[@role='row']/td[5]/a" ) url_list = [url.get_attribute('href' ) for url in links] json_data = [] titles = [] edb_id_list = [] authors = [] dates = [] for url in url_list: driver.get(url) title = driver.find_element(By.XPATH, "//h1" ).text edb_id = driver.find_element(By.XPATH, "//div[@class='col-sm-12 col-md-6 col-lg-3 d-flex align-items-stretch'][" "1]//div[@class='col-6 text-center'][1]/h6" ).text date = driver.find_element(By.XPATH, "//div[@class='col-sm-12 col-md-6 col-lg-3 d-flex align-items-stretch'][" "3]//div[@class='col-6 text-center'][2]/h6" ).text author = driver.find_element(By.XPATH, "//div[@class='col-sm-12 col-md-6 col-lg-3 d-flex align-items-stretch'][" "2]//div[@class='col-6 text-center'][1]/h6" ).text titles.append(title) edb_id_list.append(edb_id) authors.append(author) dates.append(date) data = { 'title' : title, 'edb_id' : edb_id, 'authors' : author, 'created' : date, } json_data.append(data) with open ('./test.json' , 'w' , encoding='utf-8' ) as json_file: json.dump(json_data, json_file, ensure_ascii=False , indent=4 ) driver.quit()
需要注意selenium 的使用语法,建议一步一步来,不要一下子把代码写到底,当然遇到问题解决问题就行。我遇到的一个报错:
1 2 3 element = driver.find_element(By.XPATH, '//tbody/tr[@role="row"][1]/td[5]/a/@href' ).text
在XPath中,如果想获取一个元素的属性值,通常需要使用@符号,但是不能直接在find_element_by_xpath方法中返回属性,不过对于获取文本是没有关系的。解决方法是先定位到元素,然后再获取其属性值。正确用法
1 2 element = driver.find_element(By.XPATH, "//tbody/tr[@role='row'][1]/td[5]/a" ) href_value = element.get_attribute('href' )
报错不可怕,可怕的是没有报错又找不出问题所在。
运行结果:
关于selenium 的使用,在网上看到一篇总结得比较好的,一并推荐给大家:
另外,爬虫的写法还有很多,也有很多现成的库供我们使用。这里只是给自己前段时间这方面的复习做个记录。